1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| import DoxcToStr as doc
import PDFToStr as pdf
import os
import atexit
import wx
import useHanLP as HanLP
class Acc(wx.Frame):
def __init__(self):
wx.Frame.__init__(self,None,0,'Acc',size = (700,400))
# 创建面板
panel = wx.Panel(self,1)
# 显示文件路径
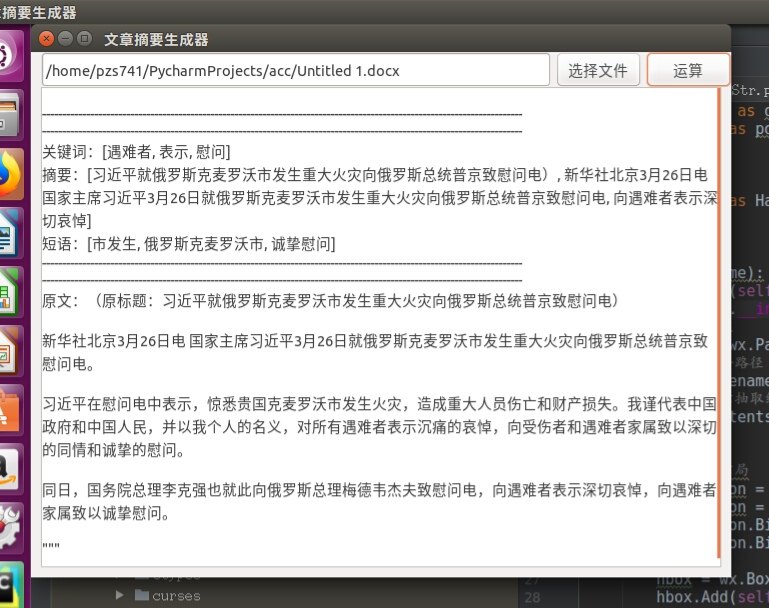
self.filename = wx.TextCtrl(panel, 3,"显示文件路径")
# 显示文章抽取结果
self.contents = wx.TextCtrl(panel, 2,"显示文章抽取结果",style=wx.TE_MULTILINE)
# 控件和布局
loadButton = wx.Button(panel, 4,'选择文件')
saveButton = wx.Button(panel, 5,'运算')
loadButton.Bind(wx.EVT_BUTTON, self.OnOpen)
saveButton.Bind(wx.EVT_BUTTON, self.OnSave)
hbox = wx.BoxSizer()
hbox.Add(self.filename,proportion=1,flag = wx.EXPAND)
hbox.Add(loadButton,proportion=0,flag = wx.LEFT,border = 5)
hbox.Add(saveButton,proportion=0,flag = wx.LEFT,border = 5)
vbox = wx.BoxSizer(wx.VERTICAL)
vbox.Add(hbox, proportion=0, flag=wx.EXPAND|wx.LEFT,border = 10)
vbox.Add(self.contents, proportion=1, flag=wx.EXPAND|wx.LEFT|wx.BOTTOM|wx.RIGHT, border=10)
panel.SetSizer(vbox)
# 选择文件
def OnOpen(self,click):
if click:
# parent, message=None, defaultDir=None, defaultFile=None, wildcard=None, style=None, pos=None, size=None, name=None
dialog = wx.FileDialog(parent=None, message='选择一个文件', defaultDir=os.getcwd(),style=wx.FD_OPEN)
if dialog.ShowModal() == wx.ID_OK:
self.filename.SetValue(dialog.GetPath())
dialog.Destroy()
# 运算
def OnSave(self,click):
if click:
filepath = self.filename.GetValue()
if filepath == '' or filepath == '显示文件路径':
self.contents.SetValue('必须选择一个文件!!!')
else:
fileExtension = filepath.split('.')[-1]
if (fileExtension == 'docx' or fileExtension == 'doc'):
res = doc.WtoT(filepath)
elif (fileExtension == 'PDF' or fileExtension == 'pdf'):
res = pdf.GetPDF(filepath)
else:
self.contents.SetValue('必须是DOC或者PDF文件!!!')
content = """
------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
关键词:{}
摘要:{}
短语:{}
------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------
原文:{}
""".format(res[0], res[1], res[2],res[3])
self.contents.SetValue(content)
if __name__ == '__main__':
# 定义程序对象
app = wx.PySimpleApp()
# 创建顶层窗口
frame = Acc()
frame.Show()
# 界面死循环
app.MainLoop()
#关闭JAVA虚拟机
atexit.register(HanLP.StopJVM())
|