def queryMySQL1(conn,table,filemd5): #通过数据库链接对象获得游标 cur = conn.cursor() sql = 'SELECT id FROM '+ table +' WHERE filemd5=%s' cur.execute(sql,filemd5) #返回一个结果 return cur.fetchone()
def insertMySQL(conn,table,filename,filepath,filemd5,filefen): cur = conn.cursor() sql = 'insert into '+table+'(filename,filepath,filemd5,filefen) values (%s,%s,%s,%s)' cur.execute(sql,(filename,filepath,filemd5,filefen)) conn.commit() cur.close() print('insert successfully!!!')
import math import json import hashlib import os import useMySQL from DoxcToStr import WtoT
conn = useMySQL.connectMySQL()
TABLE = 'filetable'
#初始化文件 def initFile(): path = './data/' for filename in os.listdir(path): filepath = path + filename name = filename.split('.')[0] filemd5 = '' with open(filepath,'rb') as f: m = hashlib.md5() m.update(f.read()) #文件MD5 filemd5 = m.hexdigest() if filemd5 is not '': res = useMySQL.queryMySQL1(conn,TABLE,filemd5) if res is None: fen = WtoT(filepath)
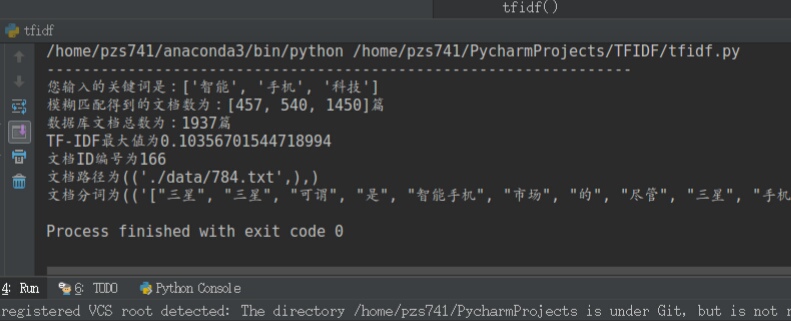
def tfidf(): keylist = ['科技','头条','男人'] #关键词出现的文章 reslist = [] for key in keylist: l = useMySQL.queryMySQLnum(conn,TABLE,key) reslist.append(l) print(reslist) #tfidf keydict = dict() for l in reslist: for ll in l: keydict[ll] = 0 #获得文档库中文档总数 allFileNum = int(useMySQL.queryALLFileNum(conn,TABLE)[0][0])
i = 0 for idL in reslist: fileNum = len(idL)+1 idf = math.log(allFileNum/fileNum)
tf = 0 for id in idL: fenres = useMySQL.queryMySQLFen(conn,TABLE,id) # print(fenres) djson = json.loads(fenres[0][0]) allwordNum = len(djson) wordNum = djson.count(keylist[i]) tf = wordNum/allwordNum