1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
| setting:
MEDIA_ROOT = os.path.join(BASE_DIR,'media')
MEDIA_URL = '/media/'
models:
import jieba
import hashlib
import json
import os
from django.core.files import File
from django.db import models
from django.core.files.storage import FileSystemStorage
# Create your models here.
from django.utils.encoding import force_text
def getStopword():
stopwordPath = os.getcwd() + '/apps/utils/stop_words.txt'
with open(stopwordPath,'r') as f:
stopwordlist = f.read().replace(' ','').replace('\n',' ').split(' ')
stopwordlist.append('\n')
stopwordlist.append(' ')
return stopwordlist
def initfile(filepath):
stopwordlist = getStopword()
with open(filepath,'rb') as f:
m = hashlib.md5()
m.update(f.read())
filemd5 = m.hexdigest()
with open(filepath, 'r') as f:
text = f.read()
fence = jieba.cut(text)
fencelist = []
for f in fence:
if f in stopwordlist:
continue
fencelist.append(f)
fenceJson = json.dumps(fencelist,ensure_ascii=False)
if len(fenceJson)>1 :
article = ArticleModel()
article.file_name = filepath.split('/')[-1]
article.file_path = filepath
article.file_md5 = filemd5
article.file_fence = fenceJson
article.save()
# 类对象会对应数据库中的一个表
from sas.settings import MEDIA_ROOT
class ArticleModel(models.Model):
#CharField对应数据库的varchar类型
file_name = models.CharField(max_length=50,verbose_name='文章名称')
file_path = models.CharField(max_length=150,verbose_name='文章路径')
file_md5 = models.CharField(max_length=32,verbose_name='文章MD5')
file_fence = models.TextField(verbose_name='文章分词')
#重新定义一些属性
class Meta:
#表的别名
verbose_name = '文章信息'
#此项不定义则别名后会存在字符s(英文框架造成的)
verbose_name_plural = verbose_name
#不重写则在返回数据时默认返回类名称,即返回文章名称为类名称
def __unicode__(self):
return self.file_name
class MyStorge(FileSystemStorage):
#删除重复上传的文件
def get_available_name(self, name, max_length=None):
filepath = os.path.join(MEDIA_ROOT,name)
if self.exists(name):
os.remove(filepath)
return name
#保存文件的同时对文章进行分词处理
def save(self, name, content, max_length=None):
"""
Save new content to the file specified by name. The content should be
a proper File object or any python file-like object, ready to be read
from the beginning.
"""
# Get the proper name for the file, as it will actually be saved.
if name is None:
name = content.name
if not hasattr(content, 'chunks'):
content = File(content, name)
name = self.get_available_name(name, max_length=max_length)
name = self._save(name,content)
initfile(os.path.join(MEDIA_ROOT,name))
return force_text(name.replace('\\','/'))
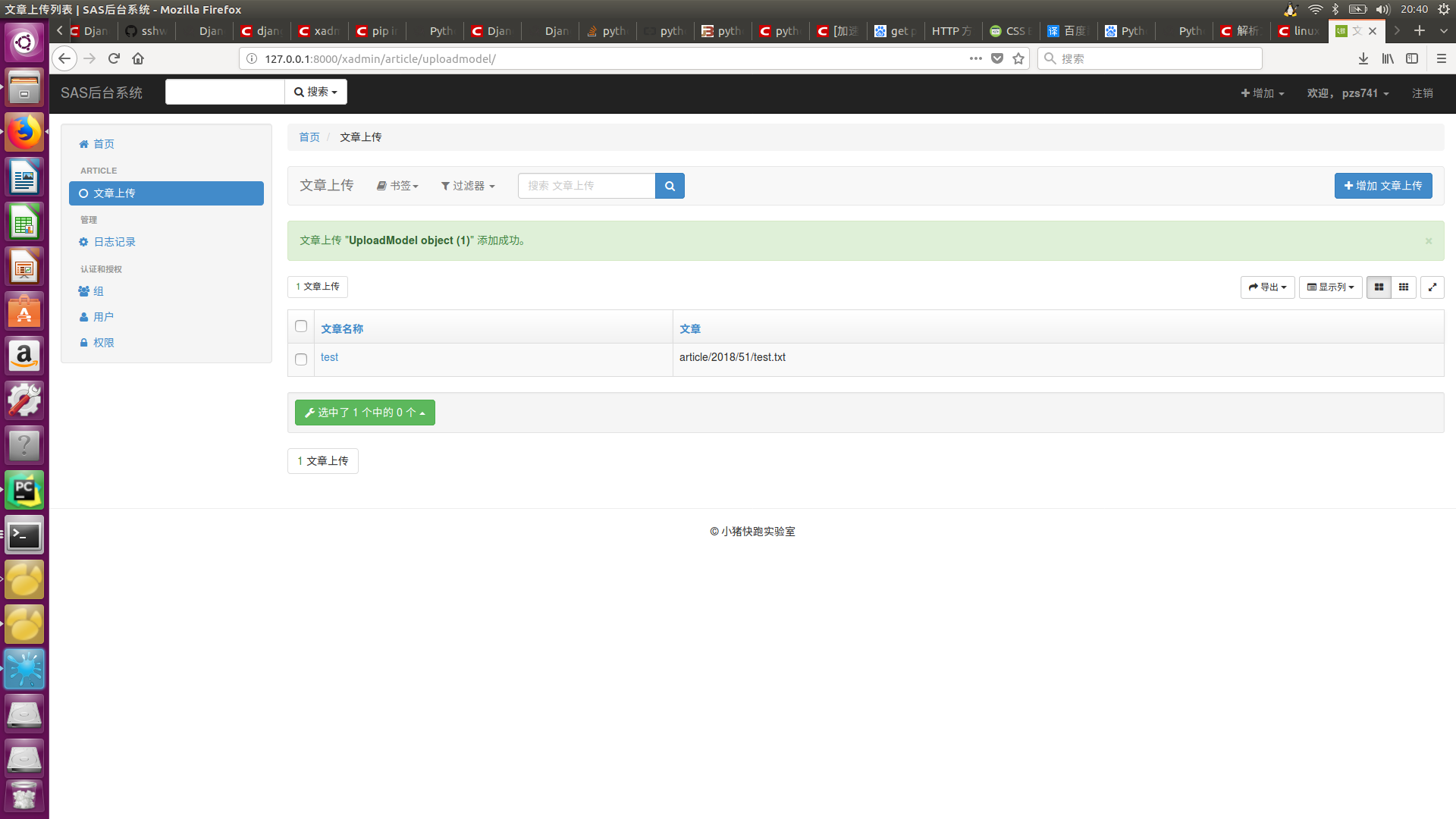
class UploadModel(models.Model):
file_name = models.CharField(max_length=50, verbose_name='文章名称')
file_path = models.FileField(upload_to='article/%Y/%M',verbose_name='文章',storage=MyStorge())
# 重新定义一些属性
class Meta:
# 表的别名
verbose_name = '文章上传'
# 此项不定义则别名后会存在字符s(英文框架造成的)
verbose_name_plural = verbose_name
# 不重写则在返回数据时默认返回类名称,即返回文章名称为类名称
def __unicode__(self):
return self.file_name
|