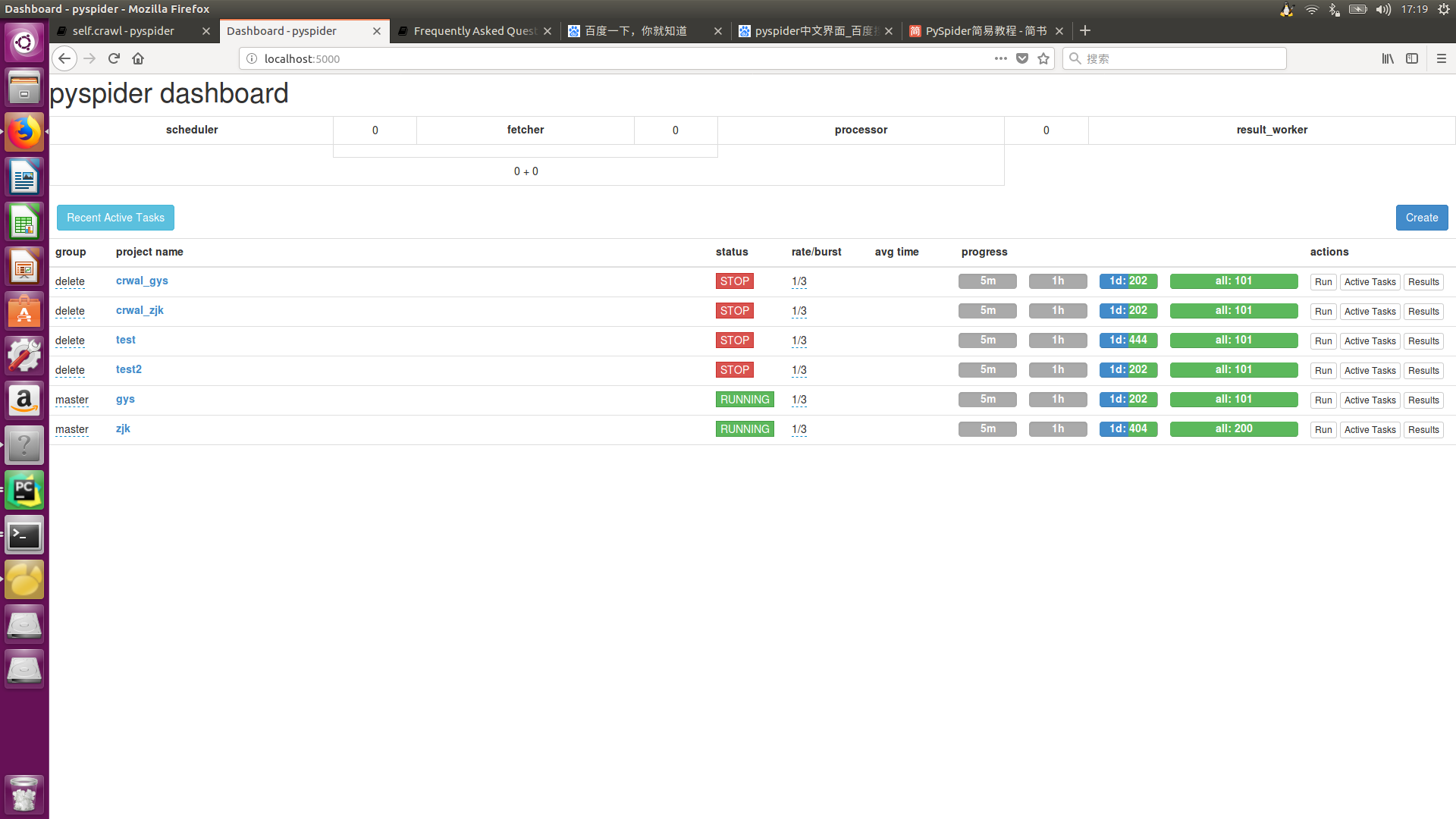
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| #!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-05-18 20:17:17
# Project: test
from pyspider.libs.base_handler import *
import MySQLdb
import MySQLdb.cursors
import hashlib
def get_md5(data):
m = hashlib.md5(data.encode("utf-8"))
return m.hexdigest()
class Handler(BaseHandler):
crawl_config = {
'itag': 'v223'
}
def __init__(self):
self.conn = MySQLdb.connect('127.0.0.1', 'root', 'root', 'pyspider', charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://localhost:8000/gys/0/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for i in range(99):
self.crawl('http://localhost:8000/gys/'+str(i)+'/', callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
url = response.url
md5 = get_md5(url)
gsmc= response.doc('#gsmcValue').text()
jjxz= response.doc('#jjxzValue').text()
gyslx= response.doc('#gyslxValue').text()
gysdj= response.doc('#gysdjValue').text()
gsclsj= response.doc('#gsclsjValue').text()
lxrxm= response.doc('#lxrxmValue').text()
lxrsj= response.doc('#lxrsjValue').text()
lxrgddh= response.doc('#lxrgddhValue').text()
lxrcz= response.doc('#lxrczValue').text()
fddbrxm= response.doc('#fddbrxmValue').text()
fddbrgddh= response.doc('#fddbrgddhValue').text()
fddbrsj= response.doc('#fddbrsjValue').text()
fddbrsfzh= response.doc('#fddbrsfzhValue').text()
lxryx= response.doc('#lxryxValue').text()
lxrdz= response.doc('#lxrdzValue').text()
zzjgdm= response.doc('#zzjgdmValue').text()
yzbm= response.doc('#yzbmValue').text()
zcdz= response.doc('#zcdzValue').text()
gswz= response.doc('#gswzValue').text()
ssdq= response.doc('#ssdqValue').text()
swdjh_gs= response.doc('#swdjh_gsValue').text()
swdjh_ds= response.doc('#swdjh_dsValue').text()
swdjfzjg_gs= response.doc('#swdjfzjg_gsValue').text()
swdjfzjg_ds= response.doc('#swdjfzjg_dsValue').text()
swdjyxq_gs= response.doc('#swdjyxq_gsValue').text()
swdjyxq_ds= response.doc('#swdjyxq_dsValue').text()
yyzzzch= response.doc('#yyzzzchValue').text()
yyzzfzjg= response.doc('#yyzzfzjgValue').text()
yyzzzczj= response.doc('#yyzzzczjValue').text()
yyzzzcd= response.doc('#yyzzzcdValue').text()
jyfw= response.doc('#jyfwValue').text()
yyzzyxq= response.doc('#yyzzyxqValue').text()
yyzzzjnjsj= response.doc('#yyzzzjnjsjValue').text()
gsjj= response.doc('#gsjjValue').text()
khyh= response.doc('#khyhValue').text()
yhzh= response.doc('#yhzhValue').text()
ctbjl= response.doc('#ctbjlValue').text()
zhtjsj= response.doc('#zhtjsjValue').text()
cpml= response.doc('#cpmlValue').text()
insert_sql = """
insert into gys(url,md5,gsmc, jjxz, gyslx, gysdj, gsclsj, lxrxm, lxrsj, lxrgddh, lxrcz, fddbrxm, fddbrgddh, fddbrsj, fddbrsfzh, lxryx, lxrdz, zzjgdm, yzbm, zcdz, gswz, ssdq, swdjh_gs, swdjh_ds, swdjfzjg_gs, swdjfzjg_ds, swdjyxq_gs, swdjyxq_ds, yyzzzch, yyzzfzjg, yyzzzczj, yyzzzcd, jyfw, yyzzyxq, yyzzzjnjsj, gsjj, khyh, yhzh, ctbjl, zhtjsj, cpml)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
try:
self.cursor.execute(insert_sql, (url,md5,gsmc, jjxz, gyslx, gysdj, gsclsj, lxrxm, lxrsj, lxrgddh, lxrcz, fddbrxm, fddbrgddh, fddbrsj, fddbrsfzh, lxryx, lxrdz, zzjgdm, yzbm, zcdz, gswz, ssdq, swdjh_gs, swdjh_ds, swdjfzjg_gs, swdjfzjg_ds, swdjyxq_gs, swdjyxq_ds, yyzzzch, yyzzfzjg, yyzzzczj, yyzzzcd, jyfw, yyzzyxq, yyzzzjnjsj, gsjj, khyh, yhzh, ctbjl, zhtjsj, cpml))
self.conn.commit()
except:
pass
|