

基于WEB工作文档的知识库构建算法介绍
介绍一个共分为四个部分,首先我们将阐述知识库构建算法的设计思路,而后我们将分别介绍抽取算法、挖掘算法和问句生成算法,最后我们将对我们提出的算法作出总结。

算法设计考虑到算法的通用性,只要是WEB文档,不管是产品手册、案例文档、还是用户指南,都要能广泛适用。
WEB文档含有大量的网页噪声,抽取算法应该能有效的避免网页噪声,抽取主体内容。
只要是符合问答标准的信息,不管是关键词、短语还是句子都要能被挖掘算法检测出来,保证最大化挖掘问答信息对。
由于WEB文档规范性较高,答案一般具有较强的规范性和针对性,因此我们将重点集中在如何将含有关键词、短语、句子的序列组合生成高质量的问题信息。

那么,我们要如何保证算法的通用性呢?
我们采用基于行块分布函数的正文抽取算法,解决抽取算法的通用性问题,我们分别提出了EMDT基于Web文档密度和标签的问答对抽取及挖掘算法和QGDT基于模板和深度学习的问句生成算法,分别解决了尽量多的挖掘问答信息对,和尽量好的生成高质量问答对这两个知识库构建的重点和难点问题。

下面我们开始介绍EMDT抽取挖掘算法

第一部分:基于行块分布函数的正文抽取算法。

对于一个WEB文档来说,如果去除了所有的HTML标签和CSS样式,只保留文本行和分隔符后,那么WEB文档中的文本块的分布就如左图所示,x轴为文本块的序号,y轴为文本块的长度,可以清晰的看到,正文主体部分非常突出,我们利用以下几个特点建模并抽取正文:
- 第一点:正文的开始到结束的内容具有连续性
- 第二点:在给定的窗口的中,窗口内的正文的文本块大小不为零
- 第三点:正文的头部之前和尾部之后必然会出现文本块大小为零的情况也就是出现换行符\n
- 第四点:在指定的窗口内,文本块大小之和最大的部分一定出现在正文内。
我们根据以上特征对WEB文档进行建模,其约束条件已经分别给出,我们依靠该算法去除了网页源噪声,保留了正文主体部分的网页源代码,供下一步的挖掘使用。

下面我们介绍基于网页DOM树技术的挖掘算法:
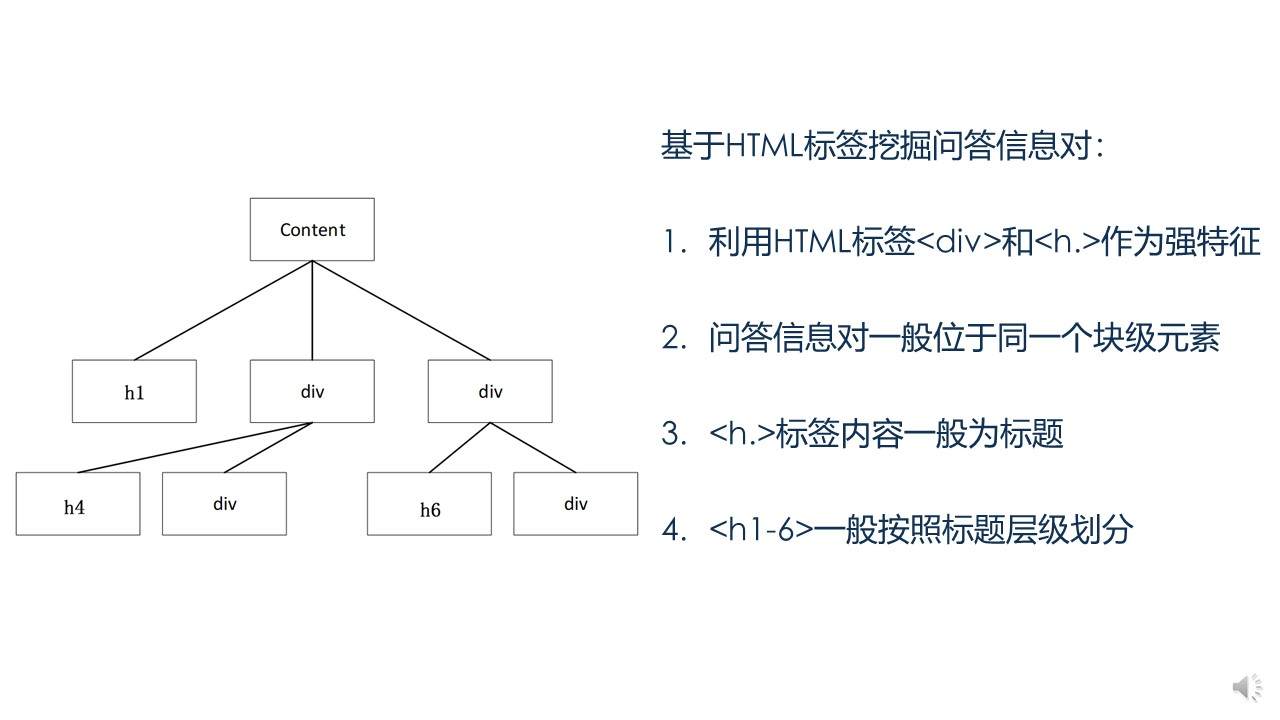
我们知道网页源代码可以解析成一个个文档对象模型,即网页DOM-tree,在DOM树中,我们发现并且认为< h >标签和< div >标签是两个非常重要的特征,如果我们只关注这两个标签,正文主体部分的源代码解析后一般如左图所示:
实践证明,具有问题特征的信息一般被放到< h >标签内作为标题,并且< h >标签从1-6的分布一般是按照层级关系书写,另外一个特点是,具有问答特征的信息通常被至于块级元素< div >标签内。
我们以< h >标签和< div >标签为强特征,深度遍历整个DOM树,找出所有同时具备这两个标签的结点,而后依据深度挖掘的顺序和< h >标签1-6的权重关系,挖掘出所有具备以上所述特征的父亲结点和对应的子孙结点,挖掘生成的问题我们按照主题、父问题、子问题的顺序组成问题序列,我们称之为搜索词,需要注意的是它并不是最后的问题信息,关于问句的生成我们将在后面重点介绍。需要额外补充说明的一点是,关于主题信息我们一般通过< title >这个强标签进行抽取,也可以辅以规则进行更精确的抽取。

下面我们介绍问答对判定模型
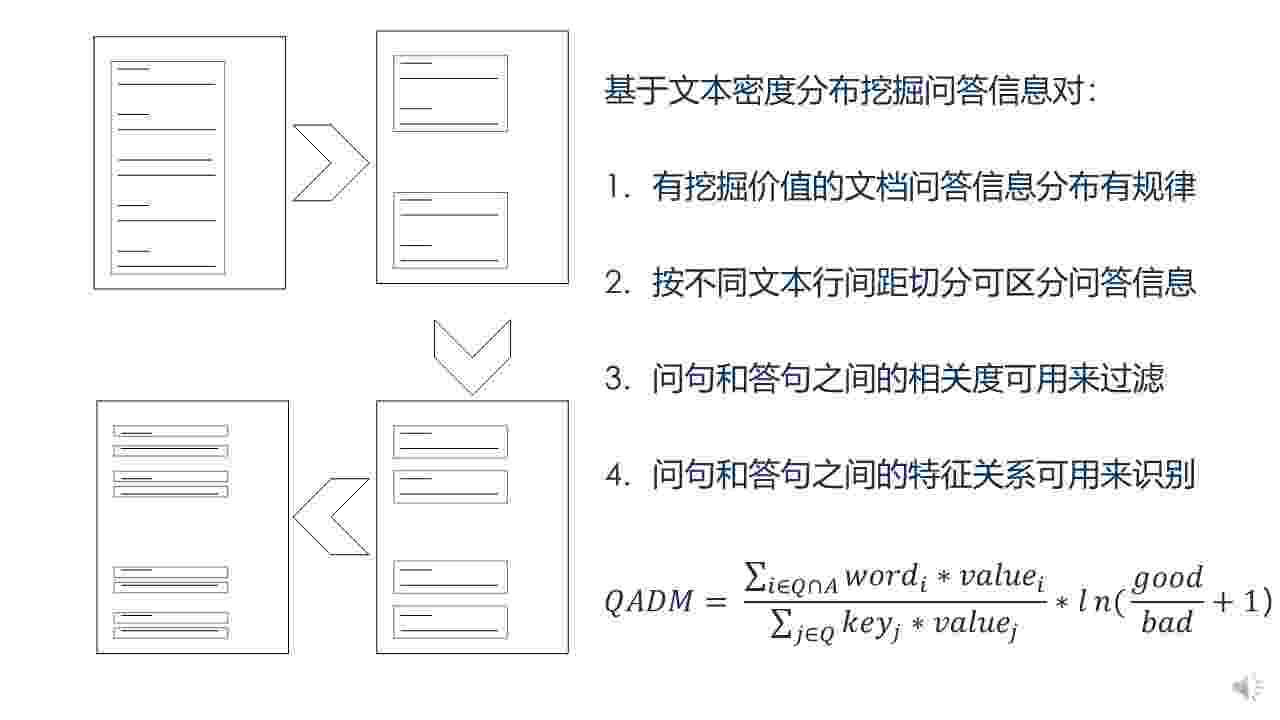
这是第二种挖掘算法,适用于无法通过强标签特征挖掘问答信息的的WEB文档,是我们对问答对挖掘算法的有力补充。
通过观察左图WEB文档的文本分布,我们可以看到,具有挖掘价值的WEB文档的文本分布一般具有规律性,即标题—正文,小标题—正文,换句话说,即文本行行间距可以用于切割WEB文档,区分不同问答对信息,因此我们提出了最大迭代切割算法来挖掘问答对信息:
首先去除正文主体所有的标签信息,只保留文本行和换行符,我们称之为密度化,进一步将密度化后的文档,转换成只含有文本信息和文本行间距的文本序列,而后按照文本行间隔由大至小的顺序,依次切割文本序列,将切割后的文本序列首部作为问题信息,其余部分连接后作为答案信息,并通过jaccard系数判定问答对之间的相关性,将相关度低于0.25这个阈值的问答对信息过滤,对每次迭代切割后生成的问答对信息,通过QADM问答对判定模型进行判定,模型左侧表征的是使用TextRank加权的问答对整体相关度,右侧表征的是问答特征得分,通过QADM对问答序列排序打分,保留得分最高的单次迭代切割后生成的问答对信息。

最后,我们将抽取算法和两种挖掘算法融合,提出了EMDT,即基于WEB文档密度和标签的问答对抽取及挖掘算法。

下面我们简单阐述EMDT算法的执行流程:
首先我们批量上传并逐个读取WEB文档,先使用TEBR算法去除网页噪声并保留正文源代码,而后基于正文标签特征,和文本密度分布特征,挖掘问答信息对。一般而言,由于WEB文档的强标签特性,采用基于标签的问答对挖掘算法便能取得很高的挖掘率,约为320%,融合基于文本密度分布的挖掘算法,能够使得挖掘率提高20%,达到340%。需要特别强调的时,基于标签的挖掘算法,挖掘出的答案信息我们会保留网页源代码,这是为了在APP中渲染HTML标签,从而为用户提供更好的显示效果。

下面我们介绍问句生成算法,其目的就是为了将EMDT挖掘生成的搜索词序列,转化成符合提问习惯和产品文档规范的问句。我们提出的基于模板和深度学习的问句生成算法,使用了机器学习、深度学习、检索模型和排序算法等知识,有效解决了由词、句序列生成问句的重点难点问题。
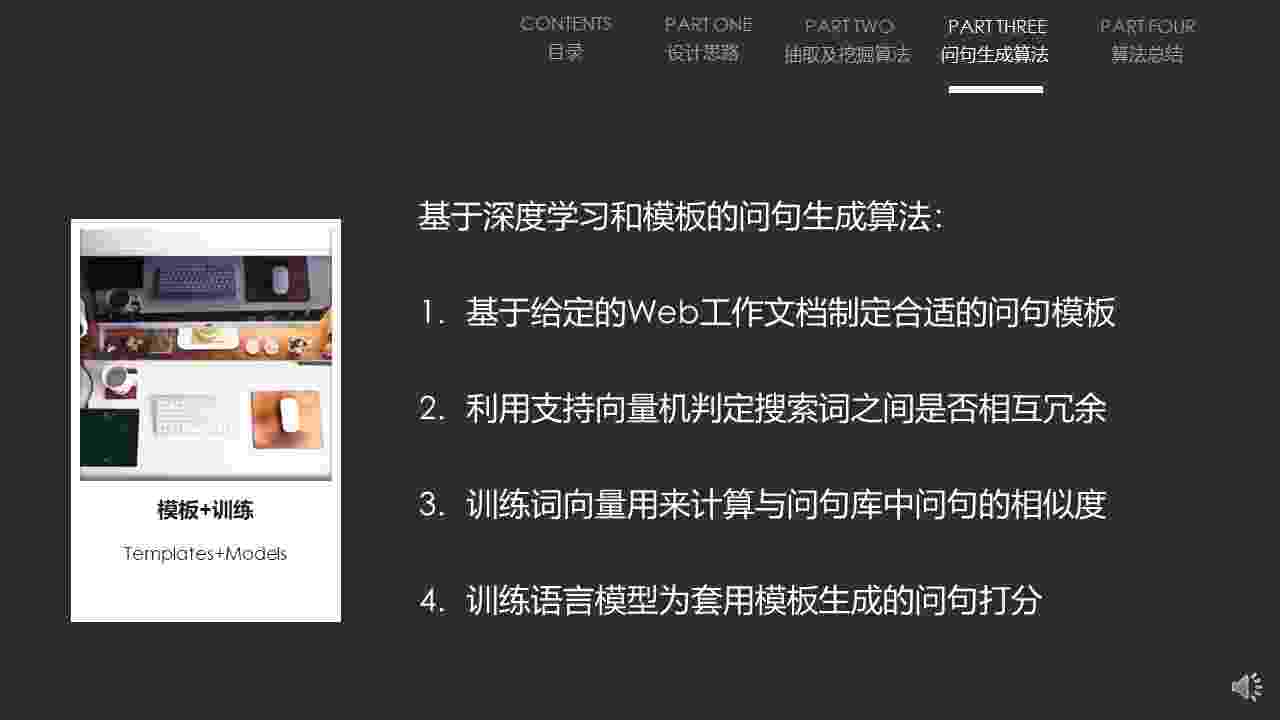
QGDT首先要求人工配置,问句生成模板若干个,人工标注一定数量的支持向量机训练集,和能覆盖WEB文档集合的Word2vec词向量训练语料以及训练RNN深度学习语言模型问句语料。
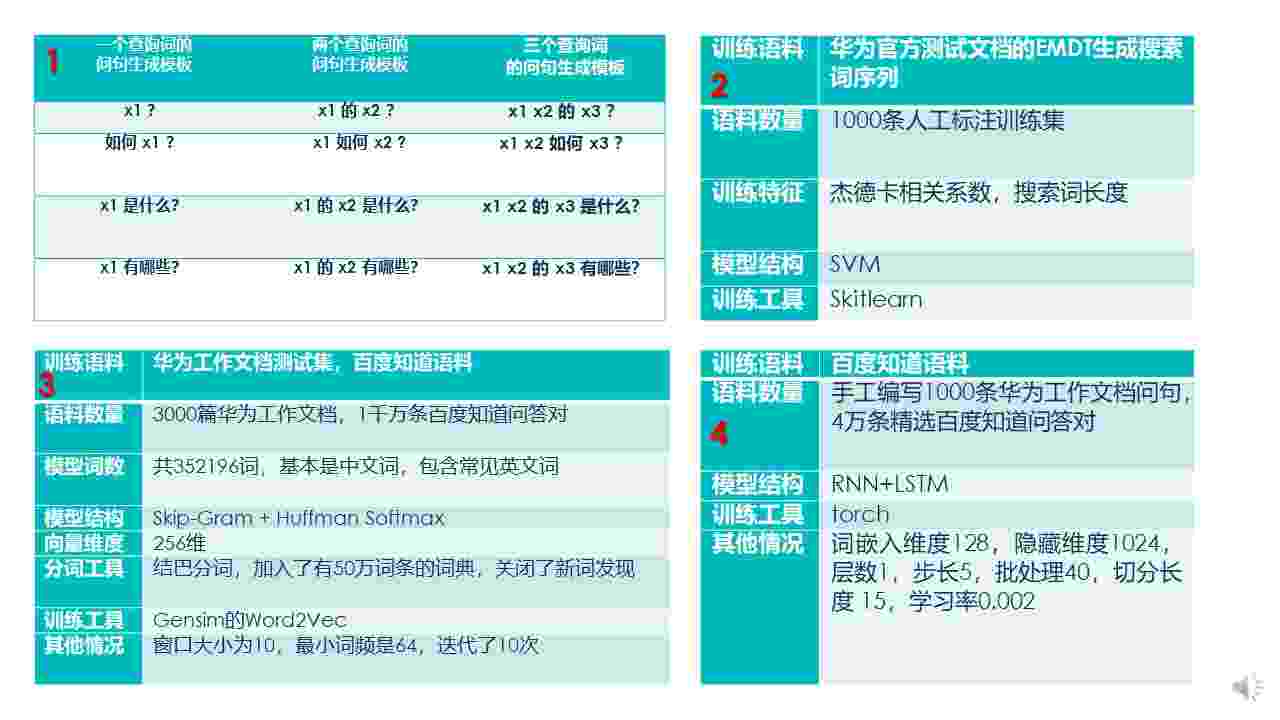
我们根据华为提供的测试集制定了12个问句生成模板,包括了4个单检索词问句生成模板、4个双检索词问句生成模板和4个三检索词问句生成模板,如表1所示。
我们人工匹配了1000条EMDT挖掘生成的搜索词序列,用来训练机器学习模型支持向量机,这1000条人工匹配的问句我们称之为模板集,支持向量机分类器用于判定搜索词序列中是否含有冗余搜索词,丢弃对于生成问句多余的搜索词,判定后的搜索词序列称为检索词序列,用于最后的问句生成,机器学习模型训练的相关参数如表2所示。
为了训练Word2Vec词向量模型,我们从百度知道爬取了一千万条问答信息,训练时加入预处理后华为测试集进行训练,确保覆盖问句生成所涉及到的所有检索词。词向量模型的训练参数如表3所示。
我们进一步处理问答语料,保留符合我们预定义问句生成模板的问句信息,约4万条,同时加入模板集,训练RNN+LSTM深度学习语言模型,深度学习神经网络相关参数如表4所示。

模板和模型训练完毕后,我们进入QGDT算法的第二部分,相似度的计算。相似度计算主要是通过了比较检索词序列与模板集的相似度,为问句生成模板排序打分,我们主要依据了word move distance基于词向量的词移距离来比较多个检索词之间的相似度,我们依据概率随机采样从模板集中选取模板,最后根据相似度计算模型为问句生成模板排序打分。
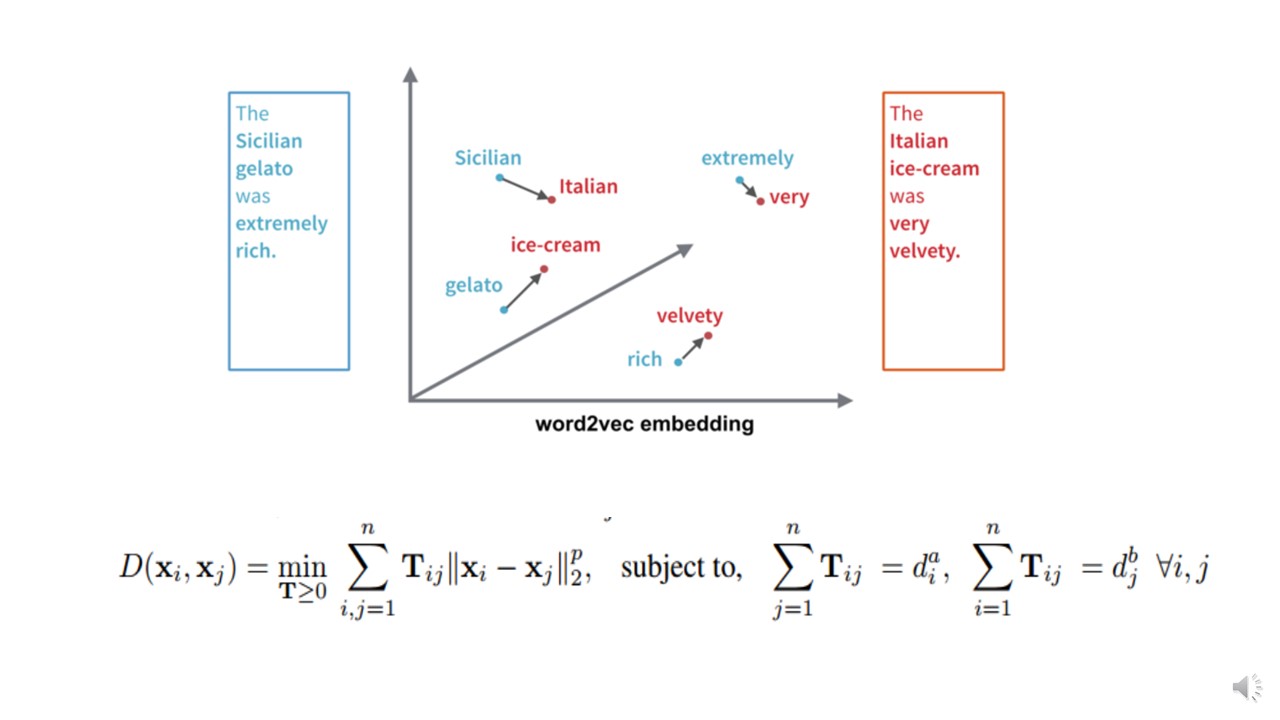
下面我们简单介绍词移距离是如何解决短语、句子或者文档等粗粒度单位的相似度比较问题。我们知道词向量模型最重要的作用是通过神经网络隐藏层将所有词压缩成低维向量表征,从而解决维度爆炸问题,通过余弦定理计算两个词之间的夹角作为相似度。
公式的含义如图所示,即左边句子中所有单词转移到右边句子的最短总距离,换句或说,两个句子间的距离就是每个单词移动距离的总和,因此称之为词移距离。
接下来介绍QGDT第三部分,频度计算,深度学习语言模型不仅解决了N-gram语言模型的维度爆炸问题,还通过循环神经网络和长短期记忆网络自动学习语言特征,使用开始标签< start or end >初始化网络后,对应的输出层参数可以表征下一个单词出现的可能,得分总和的平均,我们称之为频度。
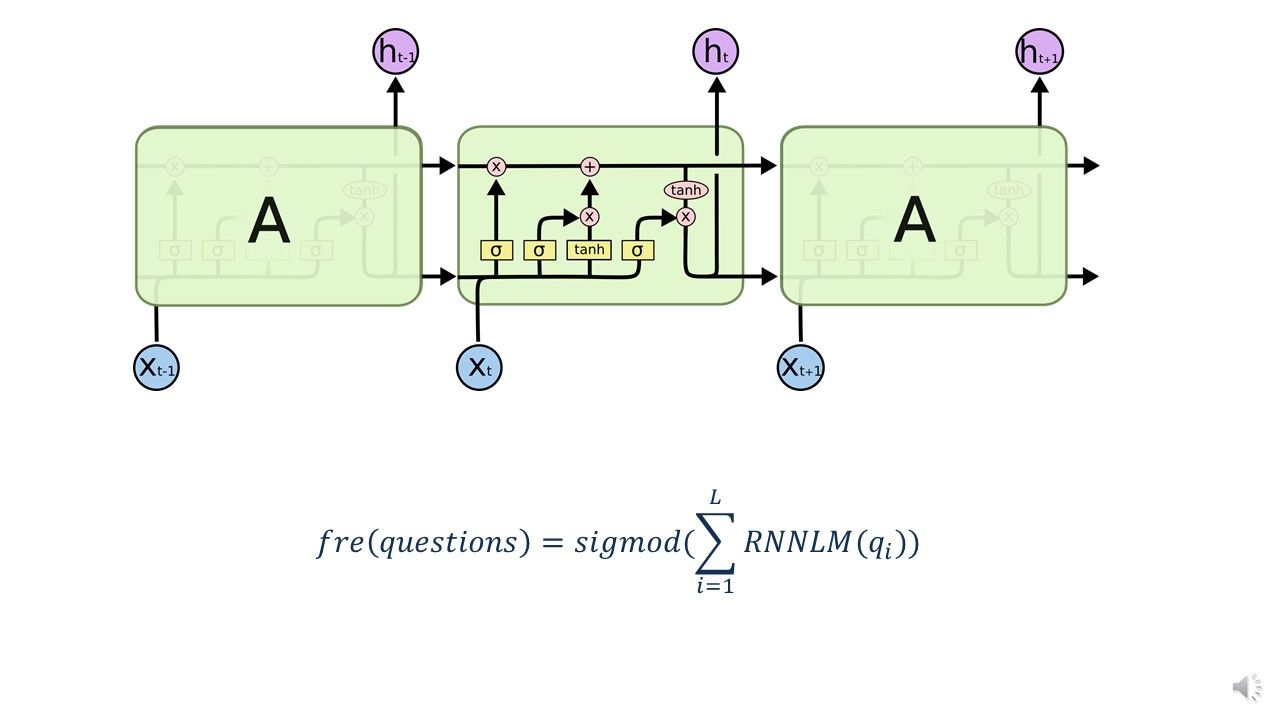
我们利用长短期神经网络的记忆特性,不但解决的概率平滑问题,还学习了问句的深度表征,该公式反映的是用RNNLM语言模型打分,并通过sigmod函数将得分归一化到[0,1]这个区间,为下一步模型融合奠定基础!

最后我们介绍QGDT的最后一部分————模型融合,相似度计算模型具有调节因子阿尔法,RNNLM语言模型具有调节因子贝塔,我们再引入融合常量纳木大,将两个模型进行线性融合,生成最终的问句生成模型,完成问句匹配模板的排序打分。
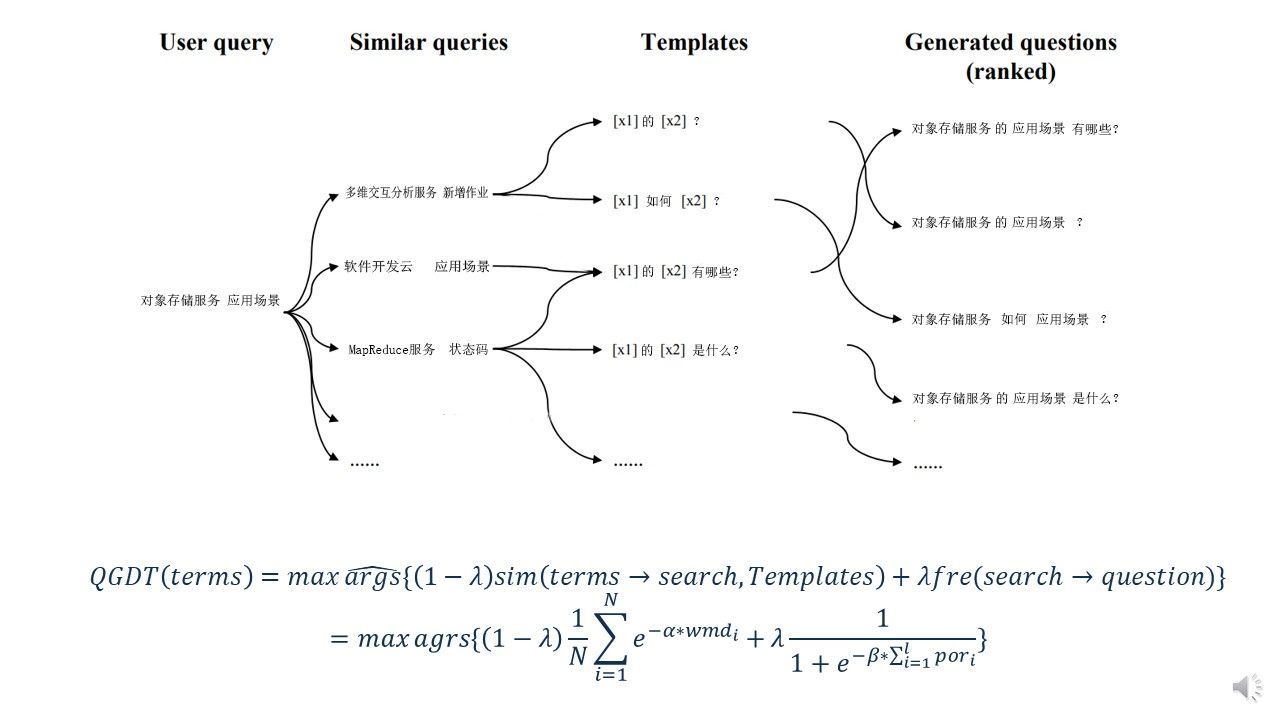
我们简单介绍QGDT的检索模型,利用预留的测试集,依次对相似度计算模型和频度计算模型进行测试,线性调整阿尔法和贝塔的取值,使得所有问句匹配模板,排序打分的差值达到最大,从而确定阿尔法和贝塔的最终取值,而后将纳木大从[0,1]线性增大,取前1平均精度作为评判指标,使得前1平均精度达到最大。至此,QGDT排序算法介绍完毕!

最后一章,算法总结,我们创造性的提出了EMDT抽取挖掘算法和QGDT问句生成算法
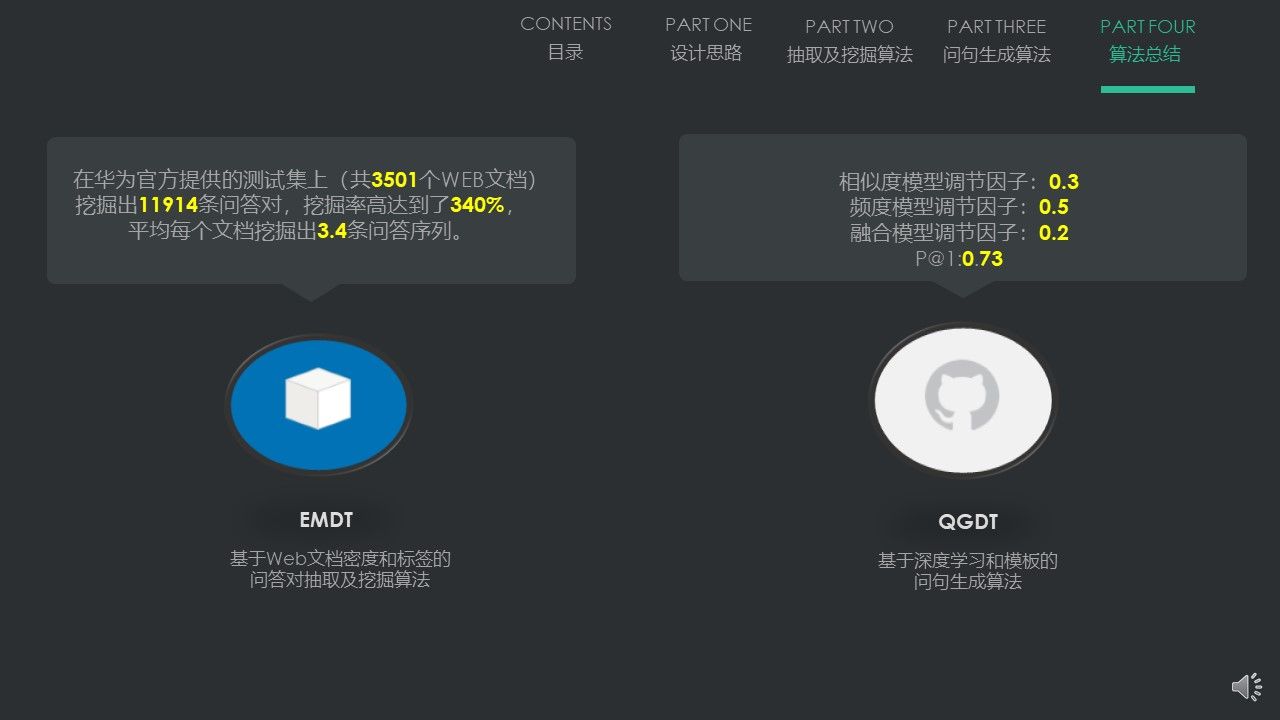
EMDT算法在华为提供的3501个测试集上,挖掘出了11914条问答对信息,挖掘率高达340%,平均每个文档挖掘出3.4条问答信息。
我们调节QGDT的两个模型调节因子和一个模型融合因子,最终,1平均精度为0.73,同时2平均精度高达0.87,有效证明了,生成的问句可接受程度非常高,基本达到了预期效果。

最后,不管是EMDT还是QGDT,都已在GITHUB上开源,上传至PYPI,提供pip的简易安装方式,其中QGDT还提供了CPU版本以供测试和云端部署,方便算法研究以及生产环境下的使用。
演示讲解完毕,感谢观看!